This appendix contains a mathematical description of the matrix algebra functions performed by FMS.
Introduction
Simultaneous Equations
The solution of the following system of simultaneous equations is one of the most important calculations in scientific analysis:A21X1 + A22X2 + . . . + A2nXn = B2
...
...
An1X1 + An2X2 + . . . + AnnXn = Bn
The calculation required is to determine the values of N unknowns X(N) from the array of known coefficients A(N,N) and vector B(N). Because the time required to solve this system increases as the cube of the number of equations N, this calculation often dominates analysis programs, resulting in limitations being placed on the analysis resolution, N.
In discussing techniques used to solve simultaneous equations, it is convenient to use the following matrix notation:
[A]{X} = {B}
where
| [A] = |
A11 A12 . . . A1n A21 A22 . . . A2n ... ... An1 An2 . . . Ann |
{X} = |
X1 X2 ... ... Xn |
{B} = |
B1 B2 ... ... Bn |
The symbol [A] denotes the N-by-N matrix of known coefficients. A single term in the matrix [A] is referred to as Aij, where the first subscript i is the row and the second subscript j is the column. The set of N known values in {B} is called the right-hand side vector while the set of N unknown values represented by {X} is called the solution vector.
Systems of simultaneous equations are often used to solve boundary value problems in the fields of structural mechanics, thermal analysis, fluid mechanics, diffusion, and electromagnetics. For these applications, the vector {X} usually represents unknown values of the field variable at sample points distributed throughout the domain of the problem. The vector {B} contains the known boundary condition values at the sample points. The matrix [A] serves as a mathematical model of the domain, relating the known boundary conditions {B} to the unknown field variable values {X}. The number of sample points, N, generally determines the resolution of the analysis.
As an example, suppose a structural analysis is performed. The matrix [A], known as the stiffness matrix, serves as a mathematical model of the object being analyzed. The vector {B} contains loads that are applied to the object [A], resulting in the displacements {X}.
Several techniques are currently used for generating simultaneous equation models of boundary value problems. Among the most popular are finite elements, finite difference, boundary integrals and the moment method. Simultaneous equations can also be generated directly from a model of discrete elements, as occurs in power network and electrical circuit analysis.
Related Systems of Equations
Often several related systems of equations that all have the same coefficient matrix [A] must be solved. For example, each vector {B}may represent a different set of boundary conditions that are applied to the same object [A]. If the systems are independent, where the values of each {B} do not depend on the previous solutions {X}, then all systems may be solved at the same time.FMS includes special features for parallel processing of multiple right-hand side and solution vectors that provide extremely fast processing of related systems of equations. Therefore, the symbols {X} and {B} are used throughout this manual to mean one or more vectors.
Linear and Nonlinear Systems of Equations
Systems of simultaneous equations can be linear or nonlinear. For linear problems, the matrix coefficients Aij are constant, while for nonlinear problems they depend on the solution values {X}. Nonlinear problems are usually solved as a sequence of linear problems, with the solution values {X} used to update the matrix coefficients Aij at each stage of the analysis. FMS contains several features that minimize the amount of computation performed when only some of the matrix coefficients Aij are changed.Matrix Symmetry and Data Type
The matrix [A] can be symmetric, Hermitian or nonsymmetric. The corresponding values in the upper and lower triangle of a symmetric matrix are equal, Aij = Aji. For a Hermitian matrix, the upper triangle terms are the complex conjugate of the lower triangle terms and the diagonal terms are real.Many boundary value problems produce symmetric matrices because the influence of one point i on another point j is the same as the influence of point j on point i. The property of symmetry is used in the equation solving algorithm to eliminate almost half of the matrix data storage and computation. The more general case of nonsymmetrical matrices, which provides for arbitrary coefficients Aij, is also included.
The data type can be real or complex. Real data requires only a single floating-point value to represent each term, while complex data requires both the real and imaginary parts. In addition to requiring twice as much storage, complex data requires four times as much processing because cross-products between the real and imaginary parts must be evaluated. For example, it requires one multiply(*) and one add (+) to compute the following for real data:
However, for complex data, the calculation becomes the following:
Uppercase letters denote the real part of the data, lowercase letters denote the imaginary part of the data, and i is the square root of (-1). The real and imaginary parts of the data are computed as follows:
A = B + C*D - c*d a = b + C*d + c*DThis computation requires four multiplies(*) and four additions (+ or -).
To optimize the use of memory pipelines, complex data is stored as the real part followed by the imaginary part. This storage is the default for variables typed COMPLEX in FORTRAN programs.
Profile Matrix Storage
FMS uses profile sparsity storage to account for large areas of the matrix [A] that may be zero. The original matrix is stored by lower triangular part [AL], diagonal [D], and upper triangular part [AU] as follows:[A] is stored by rows, starting at the first nonzero term and proceeding across the row up to, but not including, the diagonal. Similarly, [AU] is stored by columns, starting at the first nonzero term and proceeding down the column to, but not including, the diagonal. The diagonal is stored as a separate vector.
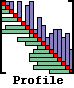
A profile vector {LOWEQ} is used, which completely describes the profile sparsity of the matrix. This vector contains the lowest coupled equation for each equation. For the lower triangle matrix [AL], this is the column number of the first nonzero term in each row. For the upper triangle matrix [AU], this is the row number of the first nonzero term in each column. The number of off-diagonal terms in row I of [AL] or column I of [AU] is I - LOWEQ(I). For a full matrix, all terms in the vector {LOWEQ} would be 1.
Nonsymmetric Matrices
For nonsymmetric matrices, FMS uses a single Profile Vector {LOWEQ} to describe the profiles of both [AL] and [AU]. This assumption of symmetric sparsity results in a considerably more efficient data handling algorithm than if separate profile vectors were used for [AL] and [AU]. Physically, symmetric sparsity implies that if point i couples to point j, then point j also couples to point i. The values of the compling coefficients Aij and Aji may be equal or unequal to produce a symmetric or nonsymmetric matrix. Naturally, zero matrix coefficients may be used if the profile is not symmetric.FMS profile storage includes full matrices, which always start at row and column 1, and banded matrices, which start at a constant distance from the diagonal. As discussed during the factoring process, the matrix factors may always be overlaid on the profile storage described above.
Symmetric Matrices
For symmetric matrices [A], the upper triangular matrix [AU] is the transpose of the lower triangular matrix [AL], [AU] = [AL]T. Therefore, [AU] is not required or used for symmetric matrix problems. Note that the FMS symmetric storage, which is by rows in [AL], is equivalent to storage by columns in [AU]. The FMS storage can be viewed as a generalization of the skyline format storage frequently used for symmetric matrices.Advantages of Profile Storage
Profile storage offers both mathematical and computational advantages over other methods of storing the matrix [A].Mathematical Advantages
First, the matrix factors may be overlaid on the original matrix during the factoring process, resulting in efficient use of memory and disk space. Second, each matrix factor term is computed from the corresponding term in the original matrix by subtracting an inner-product sum. Therefore, the matrix terms are transformed one-by-one from initial matrix values to final factored values without storing intermediate results. In addition to being computationally efficient, this transformation provides inherent restart capability. The ability to modify part of the matrix and restart the factoring process is a valuable property that eliminates a significant amount of processing for nonlinear problems.Computational Advantages
In addition to mathematical advantages of profile storage, there are also computational advantages for modern computers. The inner-products required to compute the matrix factor terms are computed using incremental addressing when the matrix is stored in FMS profile format. High-speed scientific computers operate the arithmetic units at a faster speed than the memory access time. To provide data at the faster rate, memory is divided into banks (interleaved). As long as memory addresses are generated sequentially, data references rotate among the memory banks to provide a data stream equal to the arithmetic processing speed. Random access of data, which results from indirect addressing or a step size other than unity, results in the arithmetic units waiting for data from memory. The profile storage described above results in the best possible performance for modern scientific computers.Vector Inner-Products
The FMS package is based on the efficient implementation of the vector inner-product. This operation requires two vectors as input and produces a scalar result. The inner-product is also called a dot product or scalar product.In FORTRAN, the vector inner-product is implemented by a function as follows:
DOUBLE PRECISION FUNCTION DOT (A, B, N)
REAL*8 A(N), B(N)
DOT = 0.0D0
DO I=1,N
DOT = DOT + A(I) * B(I)
END DO
RETURN
END
This calculation, which uses unit address increments for the vectors {A} and {B}, achieves maximum memory performance. Several modern processors contain a multiply-accumulate instruction which implements the above loop in hardware.
Factoring
Before deriving expressions for factoring the matrix [A], it is useful to examine the matrix multiplication process. Let [A] be the product of two full matrices [B] and [C], as follows:
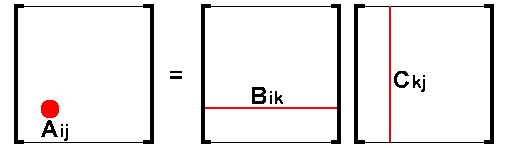
[A] = [B][C]
A typical term of the matrix [A], Aij is computed from the inner-product of the i-th row of matrix [B] and the j-th column of matrix [C],
| Aij = | N Σ k=1 |
Bik Ckj |
Nonsymmetric Factoring
The nonsymmetric factoring process consists of computing the lower and upper triangular matrices whose product equals the original matrix [A], as follows:
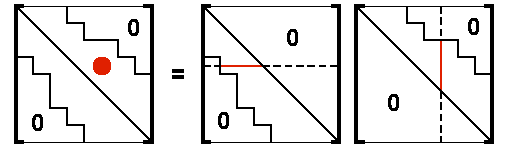
[A] = [L][U]
To obtain an expression for computing a typical term Uij in [U], consider its corresponding term Aij in [A]. Based on the matrix multiplication process described above, the term Aij is computed from the inner-product of the i-th row of [L] and the j-th column of [U],
| Aij = |
N Σ k=1 |
Lik Ukj |
| Aij = |
(IJLOW-1) Σ k=1 |
Lik Ukj | + |
(i-1) Σ k=IJLOW |
Lik Ukj | + LiiUij + |
N Σ k=(i+1) |
Lik Ukj |
The value of the first part of the inner-product is zero, because either or both of Lik and Ukj will be outside the matrix profile. For this reason profile sparsity is used on large matrices that are to be factored. The terms Lik and Ukj for k=1,(IJLOW-1) do not contribute to the matrix factors and remain zero during the factoring process.
The last part of the inner-product involving the sum from (i+1) to N will also be zero because Lik is zero for terms in the upper triangle.
In computing the factors [L] and [U], there are N(N+1) terms to be determined from the N2 terms in [A]. Therefore, N terms of [L] or [U] may be chosen arbitrarily. The choice that results in the most efficient algorithm is to select the diagonal terms of [L] to be 1. Using Lii = 1, the above equation may be solved for Uij as follows:
| Uij = Aij - |
(i-1) Σ k=IJLOW |
Lik Ukj |
Terms in the Lower Triangular Matrix
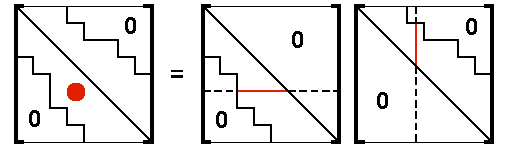 [A] = [L][U]
[A] = [L][U]
Expressions for computing terms in the lower triangular factor [L] can be derived in an identical way. Consider a term Aij that is below the diagonal,
| Aij = |
N Σ k=1 |
Lik Ukj |
| Aij = |
(IJLOW-1) Σ k=1 |
Lik Ukj | + |
(j-1) Σ k=IJLOW |
Lik Ukj | + LijUjj + |
N Σ k=(j+1) |
Lik Ukj |
The values of the first and fourth parts of the inner-product are zero as before because they involve terms outside the matrix profile or terms in the lower triangle of [U]. Solving the equation for the term Lij gives the following:
| Lij = (Aij - |
(j-1) Σ k=IJLOW |
Lik Ukj)/Ujj |
Therefore, terms in the lower triangular factor [L] are also computed by subtracting an inner-product from the corresponding term in the original matrix [A]. However, the result is then multiplied by the diagonal factor reciprocal 1/Ujj.
During the factoring and vector solution processes, the diagonals of [U] are only used as denominators. Because multiplication is faster than division, the terms Uii are inverted immediately after being computed and the reciprocal values 1/Uii are overlaid on the original matrix diagonals Aii in the diagonal vector.
Term-by-term Computation
The expressions for Uij and Lij compute the matrix factors [U] and [L] term-by-term, replacing each corresponding term of Aij as the calculation proceeds. In general, the calculations must progress from the upper left corner of the matrix A11 and end at the lower right corner Ann. The only restriction is that the terms required to compute each Uij or Lij be known from previous calculations. The actual FMS order is based on maximizing the reuse of high-speed registers once they have been loaded with data.Symmetric Factoring
The symmetric factoring process consists of computing lower triangular and diagonal matrices whose product [L][D][L]T equals the original symmetric matrix [A], as follows:
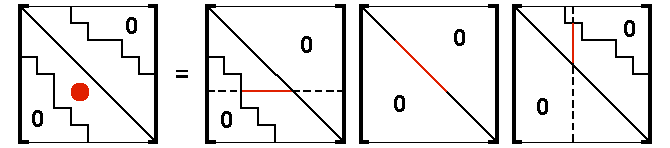 [A] = [L][D][L]T
[A] = [L][D][L]T
| Aij = |
N Σ k=1 |
Lik Dkk Ljk |
(LD)ik = Lik Dkk
| Aij = |
N Σ k=1 |
(LD)ik Ljk |
This inner-product can be divided into the following four parts:
| Aij = |
(IJLOW-1) Σ k=1 |
(LD)ik Ljk | + |
(j-1) Σ k=IJLOW |
(LD)ik Ljk | + (LD)ijLjj + |
N Σ k=(j+1) |
(LD)ik Ljk |
The value of the first part of the inner-product is zero because (LD)ik or Ljk is outside the matrix profile. The last part of the inner-product is zero because terms in the upper triangle of [L] are zero. Noting that Ljj = 1, the above equation can be solved to give the following:
| (LD)ij = Aij - |
(j-1) Σ k=IJLOW |
(LD)ik Ljk |
The final values of Lij for row i are obtained by multiplying the terms (LD)ik by the diagonal factor reciprocals 1/Dkk.
Lik = (LD)ik (1/Dkk)
Because the diagonal factors [D] are only used as denominators, they are inverted and stored in the diagonal vector as reciprocals.
Before completing the calculation for Lij the value in (LD)ij must be used to compute the diagonal factor term Dii. Letting j = i in the equation for (LD) is as follows:
| (LD)ii = Aii - |
(i-1) Σ k=IJLOW |
(LD)ik Lik |
(LD)ii = Lii Dii
and that Lii = 1, the equation for Dii becomes the following:
| Dii = Aii - |
(i-1) Σ k=IJLOW |
(LD)ik Lik |
DOT = 0.0D0
DO K = ILOW,(I-1)
LDSAVE = LD(I,K)
L(I,K) = DINV(K) * LD(I,K)
DOT = DOT + LDSAVE * L(I,K)
END DO
D(I,I) = A(I,I) - DOT
DINV(I) = 1.0D0/D(I,I)
When computing [L] and [D], the order of computation must begin at the upper left corner of the matrix A11 and end at the lower right Ann. The only restriction is that terms required to compute each Lij and Dii be known from previous calculations. Unless additional storage is to be used, the calculation of the diagonal factor Dii and the multiplication of the i-th row by the diagonal factor reciprocals must occur together, as discussed above. The actual FMS order is based on maximizing the reuse of high-speed registers once they have been loaded with data.
Vector Solution
Once the matrix [A] is factored, the following system of equations can be solved for the unknowns {X}:[L][D][L]T{X} = {B} (symmetric)
or
[L][U]{X} = {B} (nonsymmetric)
The first step is to solve the intermediate problem for the vector {Y} as follows:
[L]{Y} = {B}
For the data structure and algorithms in FMS, this is exactly the same for symmetric and nonsymmetric problems. In fact, if a symmetric matrix is processed with the nonsymmetric module, the matrix factor [L] is identical to the matrix factor [L] that would have been obtained by using the symmetric module.
An expression for computing a typical term in vector {Y}, Yi, may be obtained from the vector calculation for Bi
| Bi = |
N Σ k=1 |
Lik Yk |
| Bi = |
(ILOW-1) Σ k=1 |
Lik Yk | + |
(i-1) Σ k=ILOW |
Lik Yk | + LiiYi + |
N Σ k=(i+1) |
Lik Yk |
| Yi = Bi - |
(i-1) Σ k=ILOW |
Lik Yk |
Forward Reduction
As the calculation proceeds in the forward direction of increasing i, the terms in Yk are known when they are required to compute Yi. For this reason, this calculation is usually called forward reduction and the vector {Y} is called the reduced vector. As each term Yi is computed, it can be overlaid on the right-hand side vector term Bi.FMS stores the matrix [L] by rows and the terms Yk as a vector. Therefore the inner-product used for forward reduction produces incremental addressing that can be pipelined.
Diagonal Scaling
For symmetric matrices, the second step of vector solution is diagonal scaling. This operation computes the intermediate vector {Z} from the reduced vector {Y} as follows:[D]{Z} = {Y}
Recalling that the diagonal factor [D] was stored in reciprocal form, this calculation becomes the following:
Zi = (1/Dii) Yi
As each multiplication is performed, the values of the scaled vector Zi are overlaid on the reduced vector Yi.
Back Substitution in Nonsymmetric Problems
The final step in vector solution is back substitution. For nonsymmetric problems, this step involves solving the following equation for the solution {X}:[U]{X} = {Y}
To obtain an expression for computing {X}, consider the vector calculation to compute Yi, as follows:
| Yi = |
N Σ k=1 |
Uik Xk |
| Yi = |
(i-1) Σ k=1 |
Uik Xk | + UiiXi + |
N Σ k=(i+1) |
Uik Xk |
(XU)i = Xi Uii
the above equation can be solved for the following:
| (XU)i = Yi - |
N Σ k=(i+1) |
Uik Xk |
Xi = (XU)i (1/Uii)
As the calculations proceed in a backwards direction of decreasing i, the terms in Xk are known when they are required to compute Xi. For this reason, this calculation is usually called back substitution.
The inner-product
|
N Σ k=(i+1) |
Uik Xk |
Xi = (XU)i (1/Uii)
| (XU)k = (XU)k - |
(i-1) Σ k=ILOW |
Uki Xi |
Back Substitution in Symmetric Problems
The symmetric back substitution process is almost identical, except [L]T is used for [U] with Lii = 1. A typical term Xi is obtained from the scaled vector Zi by subtracting the inner-product as follows:| Xi = Zi - |
N Σ k=(i+1) |
Lki Xk |
| Xk = Xk - |
(i-1) Σ k=ILOW |
Lik Xi |
Matrix and Vector Multiplication
FMS includes multiply operations that occur frequently in matrix algebra. The first operation computes the following:
{C} = {D} - [A]{B}
{C} = [A]{B}
{C} = {D} + [A]{B}
{E} = {B} - [A]{X}
The resulting error can then be used in interative refinement to compute a correction to the solution {X}.
A similar set of multiply routines are provided which use submatrix files instead of the assembled matrix:
{C} = {D} - [Si]{B}
{C} = [Si]{B}
{C} = {D} + [Si]{B}
FMS also contains the following multiplication routines:
{C} = {D} - {A}{B}
{C} = {A}{B}
{C} = {D} + {A}{B}
{C} = {D} - {A}T{B}
{C} = {A}T{B}
{C} = {D} + {A}T{B}
[C] = [D] - {A}T{B}
[C] = [D] {A}T{B}
[C] = [D] + {A}T{B}
[F] = {X}T{Y}
where [F] is a full matrix and {X} and {Y} are FMS vector files containing one or more vectors. For symmetric problems, only the lower triangle of [F] is computed.
These multiply operations have several practical applications in computing Eigenvalues of the matrix [A]. For example, if {X} is a known Eigenvector, the corresponding Eigenvalue can be computed from the following:
e = ({X}T[A]{X})/({X}T{X})
This calculation uses the matrix-vectors multiply operation once and the vectors-vectors multiply operation twice.
These multiply operations are also used to project the matrix [A] into a subspace [A*] where its Eigenvalues can be computed more efficiently. This projection involves the following computation:
[A*] = {X}T[A]{X}
where {X} are the vectors that define the subspace.
In the special case where the matrix is diagonal [D], FMS directly computes the following quadratic form:
[F] = {X}T[D]{X} (symmetric)
[F] = {X}T[D]{Y} (nonsymmetric)
FMS also includes the vectors matrix multiply calculation
{Y} = {X}[F]
This calculation may be used to project subspace eigenvectors back into the problem space or to compute new vectors {Y} from a linear combination of old vectors {X}.