What Type of Problem Does FMS Solve?
Computers are used extensively in science and engineering to predict the behavior of products before they are built. The computer analysis helps in optimizing the design, improving performance and lowering cost.
 The computerized analysis is based on the division of the problem into a large number of
pieces (shown as triangles in this example).
Within each piece, a model is built which describes the behavior of that piece.
The individual pieces are then assembled together to form an overall model of the product.
FMS performs this assembly and computes the interaction among the
pieces.
The computerized analysis is based on the division of the problem into a large number of
pieces (shown as triangles in this example).
Within each piece, a model is built which describes the behavior of that piece.
The individual pieces are then assembled together to form an overall model of the product.
FMS performs this assembly and computes the interaction among the
pieces.
As the number of pieces used to model the product is increased, the approximate solution obtained from the computer approaches the exact solution of the original problem. The maximum number of pieces that can be used, and therefore the accuracy of the analysis, is determined by the capacity of the computer hardware and software.
This modeling process is often called discretization, because the original problem is replaced by a finite number of discrete pieces. Analysis programs based on this approach include finite element, finite difference, boundary integral and moment method techniques.
These formulations exploit the strength of digital computers, which perform large numbers of similar tasks rapidly.
Mathematically this simulation involves the solution of a large system of simultaneous equations
[A]{X} = {B}
where
- [A] is an N-by-N coefficient matrix that represents the product being analyzed,
- {B} is an N-by-1 right-hand side vector that represents the environment that the product is operating in, and
- {X} is an N-by-1 solution vector being computed, which represents the response of the product to the operating environment.
What Limits N?
We want to make N as large as possible, so the computer simulation closely resembles the product. In order to understand what limits N, let us look at this process in more detail.The following flowchart illustrates the steps involved in performing this type of computer simulation.
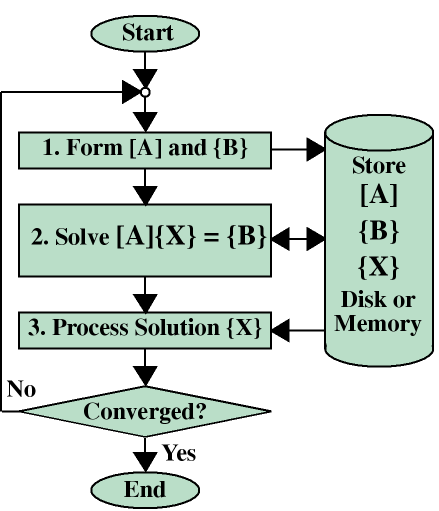
- Form [A] and {B}
The process begins by forming local equations for each of the discrete pieces. These equations are in the form of contributions to the matrix [A] and right-hand side vector {B}. For large problems, this data is usually written to disk as it is generated. - Solve [A]{X} = {B}
The local equations for each piece are then combined to form the global system of equations [A]{X}={B}, which is solved for the solution {X}. - Process solution {X}
After the global solution is complete, {X} is used to compute local results of interest within each piece.
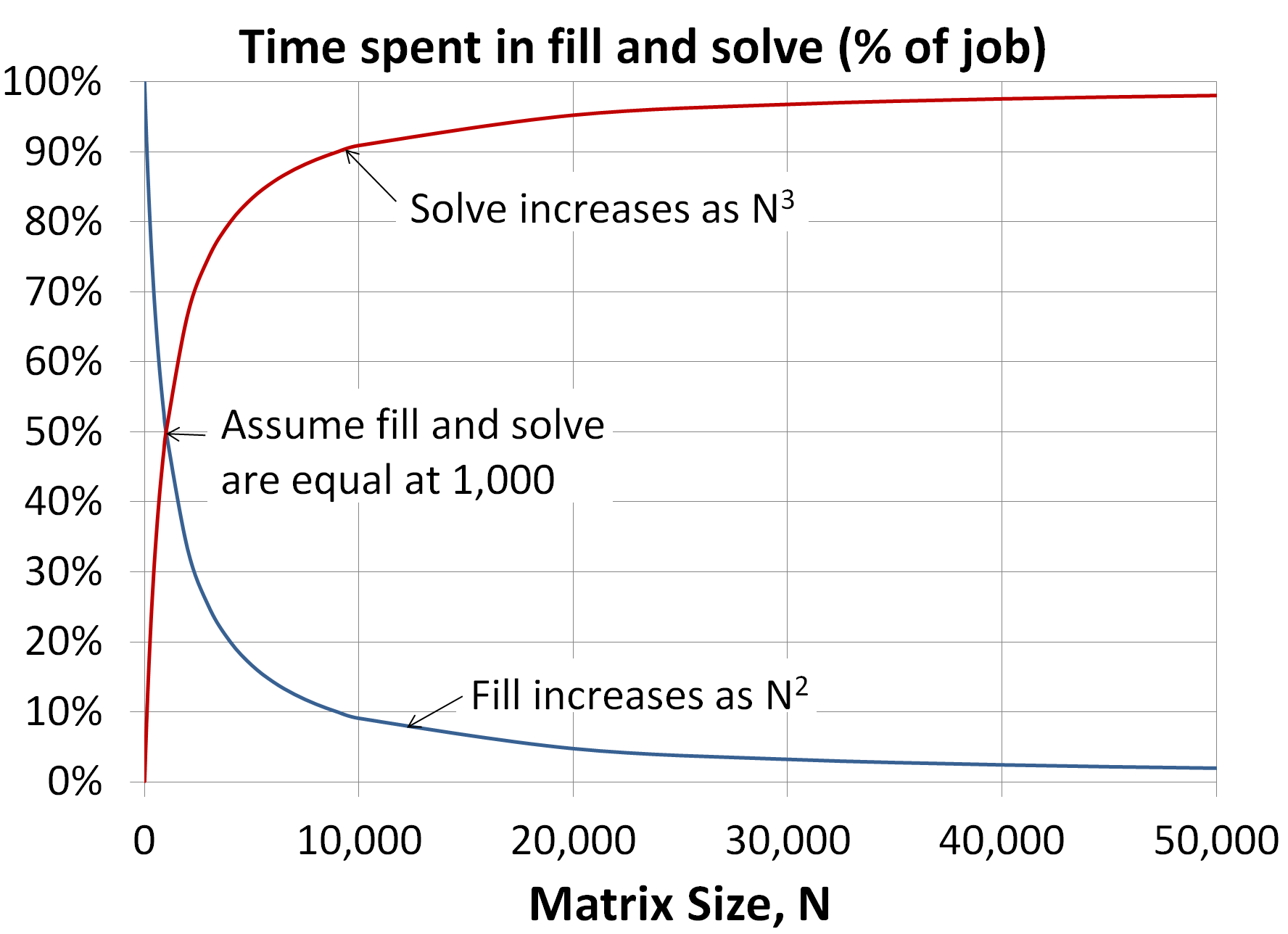
As we increase N, the time and storage requirements for Steps 1 and 3 increase differently than the requirements for Step 2. To illustrate this point, let us look at a model using a full complex nonsymmetric matrix [A] run on a computer operating at 100 Gflops. In this example, we assume that the time and storage requirements for Steps 1 and 3 are the same as Step 2 when N is 1000.
N is limited by processing time
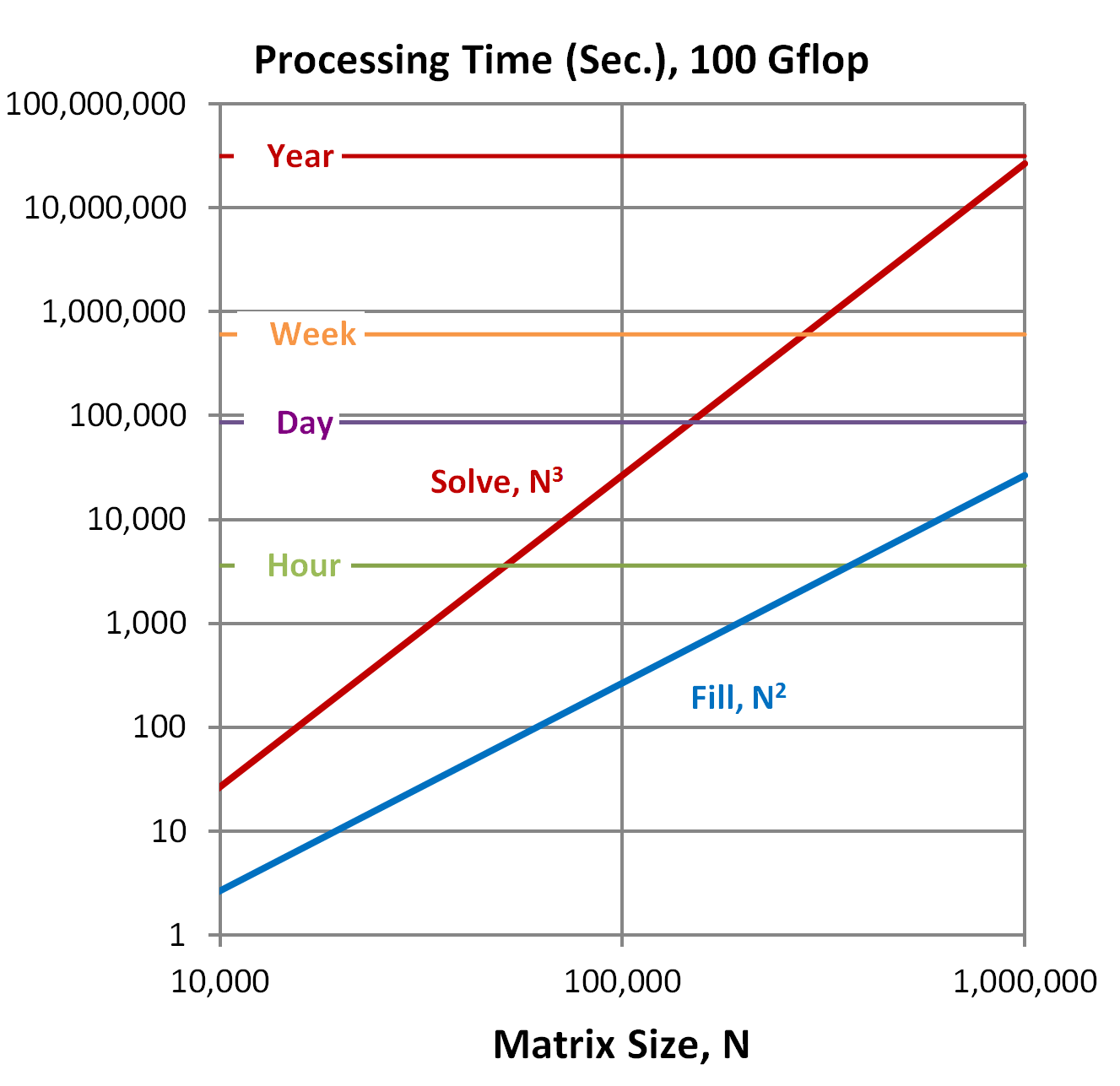 As we increase N from 10,000 to 1,000,000, the time required to fill the matrix in Step 1
increases as the square of N, N2, from less than
3 seconds to a little under 8 hours. As all elements can be formed in parallel, this
process is easily implemented
on a parallel multicore computer to achieve the desired performance.
As we increase N from 10,000 to 1,000,000, the time required to fill the matrix in Step 1
increases as the square of N, N2, from less than
3 seconds to a little under 8 hours. As all elements can be formed in parallel, this
process is easily implemented
on a parallel multicore computer to achieve the desired performance.
For the solve in Step 2, however, the scaling is drastically different. The time required to solve the system [A]{X}={B} increases as the cube of N, N3. As a result, increasing N by a factor of 100 results in the processing time increasing by a factor of 1,000,000. While a problem with 10,000 equations may be solved in less than a minute, one with 1,000,000 equations would require almost a year. Fortunately FMS supports GPU accelerators which have actually solved this problem with N=1,000,000 in a couple days. This performance continues to increase as advances are made with computer hardware.
N is limited by storage requirements
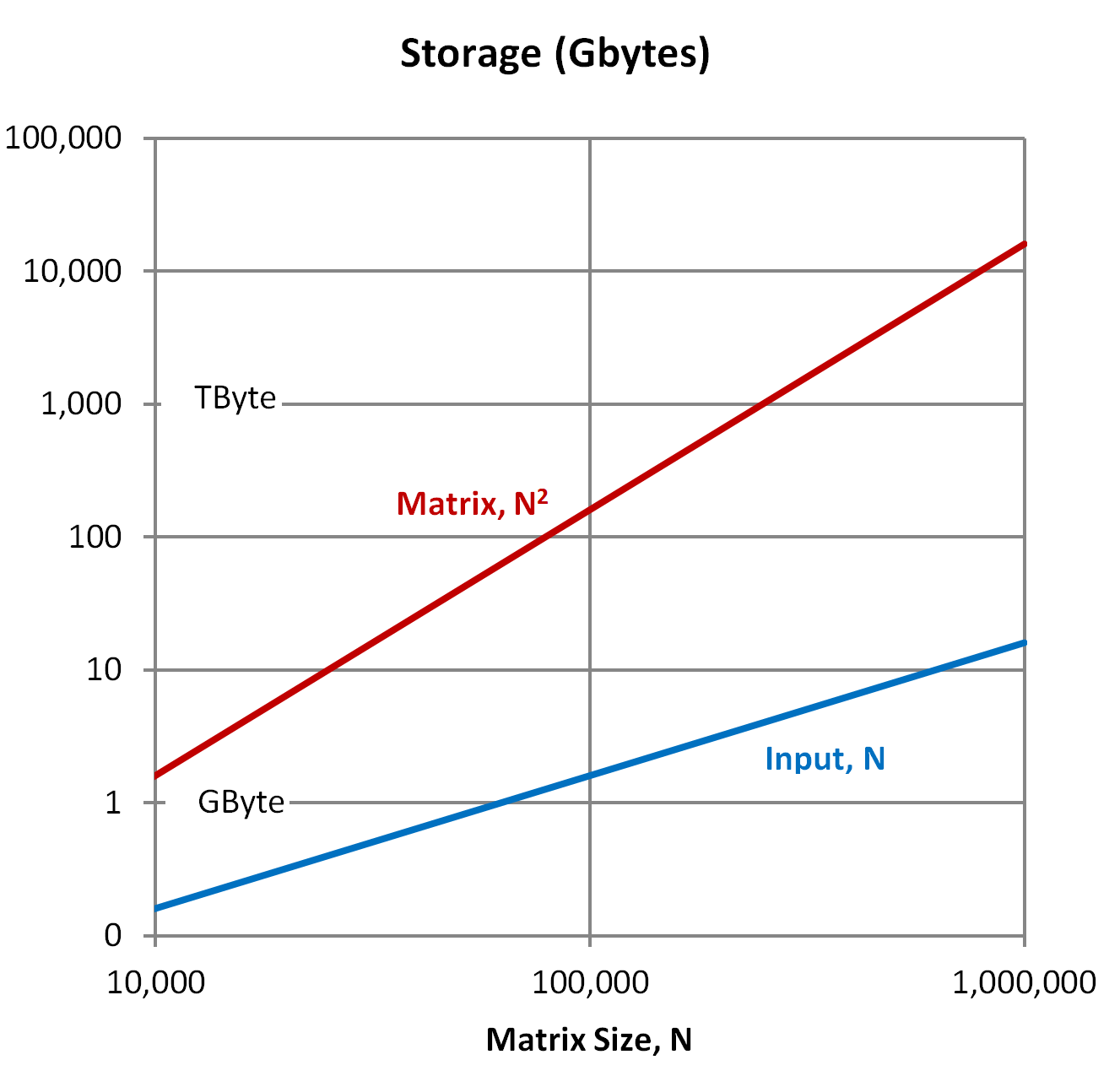 Similarly, as we increase N from 10,000 to 1,000,000, the space required for storage by
Steps 1 and 3 increases linearly, from 160 MBytes to 16 GBytes. Increasing the number of
pieces by a factor of 100 results in increasing the space required to store them by a
factor of 100.
Similarly, as we increase N from 10,000 to 1,000,000, the space required for storage by
Steps 1 and 3 increases linearly, from 160 MBytes to 16 GBytes. Increasing the number of
pieces by a factor of 100 results in increasing the space required to store them by a
factor of 100.
However, because [A] is an N-by-N array, the storage requirements for Step 2 increase as the square of N, N2. As a result, increasing N by a factor of 100 results in the storage for [A] increasing by a factor of 10,000. While a matrix of size 10,000 can be stored in 1.6 GBytes, one with 1,000,000 equations requires 16 TBytes.
This example illustrates the following barriers to increasing N:
- [A]{X}={B} is a Computational Bottleneck
As N is increased by a factor of 100, the processing time for the solution in Step 2 increases from less than a minute to almost a year! The processing time for Step 1, however, only increases to less than 8 hours. As a result, the percentage of time spent solving [A]{X}={B} rapidly approaches 100%, even for modest increases in N. - [A] Exceeds Storage Capacity
When N is 10,000, only 1.6 GBytes of storage are required for the matrix [A]. For most machines today, that means that [A] can be stored directly in memory. However, when N is increased, the storage for [A] not only exceeds memory but may also exceed the address space of the machine. For example, a machine using 32-bits of address will fail before N reaches 16,394. For large values of N, a special disk system is required. For a problem where N is 1,000,000, 16 TBytes of disk are required. - Machine Operates Inefficiently
When [A] is stored on disk, the data must be transferred to memory before processing. Disks transfer data at a rate far slower than what is required by the processor. In addition, disks must perform the transfers before processing can begin. As a result, the processors will be waiting for data most of the time. When this happens, the solution times will increase drastically.
The Solution
Fortunately there are several things that can be done to solve the above problems and allow large values of N.- Focus on [A]{X}={B}
The obstacles to increasing N listed above all occur in Step 2, the solution of [A]{X}={B}. Therefore we can focus on a well-defined mathematical problem that is generic to all modeling techniques. - Data Reuse
We noted above that the solution of [A]{X}={B} required N3 operations on N2 pieces of data. As a result, each piece of data is "reused" N times. We can use this property to design special software that stages data from disk to memory, cache and registers. At each level of storage, the data is reused as much as possible. This reduces the total amount of data being transferred, balancing large amounts of slow speed storage with smaller amounts of higher speed storage. - Parallel Processing
Today's high speed computers contain multiple processors and multiple cores within each processor. By designing software to operate these processing cores in parallel, the time required for solution can be significantly reduced. - GPU Processors
GPUs contain hundreds of multiply-add units that are ideally suited for efficiently solving the equations in Step 2. The largest supercomputers in the world achieve their performance from these GPU processors. Multiple GPUs can be configured in a single system and operated in parallel to further increase performance. - File Striping
When N is large, multiple disks will be required to store [A]. These disks can be operated in parallel to increase the rate at which data is transferred to and from memory. - Asynchronous I/O
By default, when an application requires data from disk, processing is suspended until the data has been transferred. If the disks and processors are operating at the same speed, this can double the solution time. By developing special software to read data ahead of processing, data will be available when required by the processors. As a result, the disks and processors will run concurrently and no time will be lost waiting for data.
The following figure shows the original analysis program with the equation solution phase replaced by FMS.
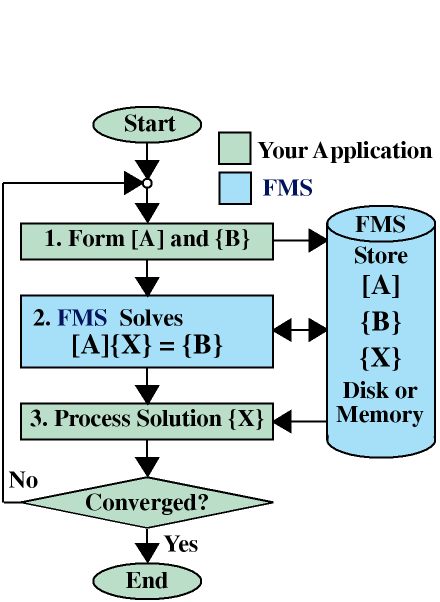
- Form[A] and
{B}
FMS captures the matrix [A] and right-hand side vector {B} as they are generated. Parts of [A] may be transferred by rows, columns, blocks, finite elements or a subroutine you provide. This data is stored directly in the FMS Database. Depending on the problem size, this database may physically reside in memory or on disk. -
Solve [A]{X} = {B}
All operations involving the matrix [A] and vectors {B} and {X} are performed by FMS, which is highly optimized for each computer system. -
Process solution {X}
FMS passes the solution vector {X} back to your application program for further processing.
Steps 1 and 3 of this analysis depend on the physics of the problem and the modeling technique used. Software and hardware efficiency are not a critical issue. By contrast, Step 2 is independent of the physics and modeling technique, but pushes the hardware to the limit. For this reason, FMS was designed from a hardware point of view.
There is an optimized version of FMS for most computer platforms. Each version makes maximum use of registers, cache, memory, disks and GPU processors. On systems equipped with multiple processors, the processors are operated in parallel to reduce runtime. On all systems, disks are operated in parallel and transfer data concurrently with processing.
While the internals of FMS are machine-specific, the interface to your application program has remained generic. This allows you to maintain a single version of your application while achieving peak performance on each computer system. FMS interrogates the hardware on startup, and automatically uses whatever is available. This allows a single binary version of your application to achieve peak performance across a wide range of hardware configurations.
FMS is High Technology Middleware
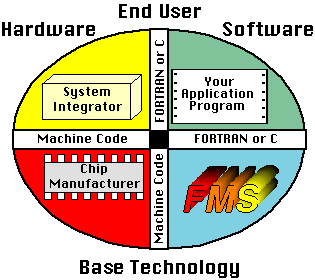
Today's computer industry consists of multiple vendors, with each vendor specializing in the products they produce. When you purchase a computer system, you are obtaining a product that was built by a team of specialists.This team may be sorted by type of technology, hardware and software, as shown in the following figure:
| System Integrator They integrate the hardware and software into a system you can use. Also included is the operating system, which may be purchased separately. |
Applications These are programs that you either develop or purchase. They perform a specific function, from word processing to sophisticated scientific analysis. |
 |
|
| Chip Manufacturer Current fabrication technology requires extremely expensive facilities to produce the fast, high density processor and memory components of today's computers. Companies specialize in this technology, producing a variety of components for various system integrators. |
Middleware At the base technology level in software is an industry called middleware. This is software that is closely coupled to the hardware and performs a generic function to a variety of applications. Database software is a typical middleware product. |
Called as a library from programs written in FORTRAN or C, FMS provides a back door to the chip and operating system technology not normally available in programming languages.
While the internals of FMS and its interface to the machine are constantly changing to take advantage of new technology, the application program interface has remained constant. This allows your applications to take advantage of new hardware technology with no development effort.
With today's world economy, maintaining a competitive advantage is critical. Products must continuously be refined to take advantage of new materials, manufacturing techniques and changing customer requirements. Computer simulations are well recognized as a vital ingredient in meeting these demands. By pushing the envelope of computer performance, FMS provides a technical advantage that helps you meet your goals.